My Command Line Usage Part 2
Welcome - in this article I'll continue detailing some command line tools that I use frequently or can often be of use to any general developer. I suggest reading through Part One for some of the more basic commands.
which
This command handily allows you to see where a program is sourced. For example, to see where my Java executable is located:
$ which java
/usr/bin/java
Environment variables
In my Part 1 article, I mentioned you can run echo $SHELL to find out if you are using bash, zsh, or another shell. But where is the computer storing this variable? How can you see what other variables there are that can be both useful to you or to change the value?
Values like $SHELL are called environment variables. All environment variables can be found by running
$ export
HOME=/Users/daniloradovic, PWD=/Users/daniloradovic/Desktop, TERM_SESSION_ID=******, etc.
A fun one is PS1= which is your terminal prompt (in my articles I use $). The default is often something like the working directory, but you can change it by exporting PS1 in your shell profile; follow this quick tutorial for more details.
In general, to change the value of an environment variable you can use the export command. For a temporary mapping you can run the command directly in terminal, otherwise you can add it to your shell profile. The general usage is
$ export [var name]=[value]
PATH environment variable
One environment variable you will have to deal with from time to time is $PATH. You can see it in the export list or by running echo $PATH. $PATH defines where your machine will check for your executable programs when you invoke the command to run them; each location is separated by :
For example, one of my paths is /usr/bin. Enter the directory on your own machine and you'll see a bunch of programs, including which, which we covered above. If a program you wish to execute is not in one of the paths listed, then you will not be able to invoke it by just calling the program name. Instead you would have to specify the path each time, which is annoying.
To append another path to $PATH, you can run export and
$ export PATH=$PATH:/path/newprogram
$PATH variable and appending after the colon.
And to prepend simply run
$ export PATH=/path/newprogram:$PATH
To add the new path to the middle of $PATH you need to copy the entire old value of $PATH into a text editor, manually insert the new path, then paste the entire new list of paths then run
$ export PATH=[full list of path]
Identify the process using a port
Sometimes you are trying to use a port on your machine but it is already in use. To see what process is using the port, any of the 3 below commands will help you identify it:
$ fuser -n tcp 8000
$ lsof -i :2009
$ curl http://localhost:8000 -v
|
| is called a "pipe". This is because it is used to pipe the output of one command as the output of another. Then, unless another pipe is used or specified otherwise, command 2 outputs to the command line as usual.
$ command 1 | command 2
As an example, let's print the contents of a file to stdout then pipe the output to wc to determine the number of lines in the file:
$ cat foo.txt | wc -l
2
pbcopy/pbpaste
These are Mac-only commands that simply allow you to copy and paste data to and from your clipboard:
$ cat foo.txt
hello there:
general kenobi
$ cat foo.txt | pbcopy
$ pbpaste
hello there:
general kenobi
$ pbpaste | grep "hello" > bar.txt
$ cat bar.txt
hello : there : general : kenobi
command + c.
xargs
xargs is used when trying to pipe like above, but command 2 cannot take the output of command 1 as input, say because it is not a flat array of inputs. So, xargs flattens the output from command 1 to a single line, which allows it to pass the results:
$ cat foo.txt
hello there:
general kenobi
$ cat foo.txt | xargs
hello there: general kenobi
Continuing from our use of wc -l, if we have a list of files in files.txt, we can check the file length of each of them using xargs:
$ cat files.txt
foo.txt
foo2.txt
$ cat files.txt | xargs wc -l
2
2
Hand in hand with piping, xargs allows you a lot more functionality and expert usage of the command line. A great read of xargs is this one from How-To Geek.
awk
awk is a powerful CLI tool that is used for searching files for queries, and can get quite complex due to being used very programmatically. For example, you can assign variable names as arguments and use those in your specified execution, such as printing. Given awk's programatic nature, I highly recommend the full set of articles that Tutorials Point takes to cover it! Here, I will just cover the general structure and an example that isn't particularly useful (because there is an easier way) but demonstrates some features of awk.
With awk, the structure of the command looks like awk [arguments] [file name where the argument can be more programmatic when wrapped in '{ }'. For example, you can print contents of a file with:
$ awk '{print}' foo.txt
Hello There
General Kenobi
Importantly, there are variables that awk uses to represent/store different properties of a line of a file. Namely, $1, $2, $3 and so on represent the fields of a line where spaces and tabs are delimiters. $0 represents the whole line.
$ awk '{print $0}' foo.txt
Hello there
General Kenobi
$ awk '{print $1}' foo.txt
Hello
General
With awk you can implement operational logic such as and (&&), or (||), and not (!).
$ awk '/error/ || /exception/ && !/fail/' some_log_file.txt
The example of awk is:
$ grep -c -i "query" *.txt | awk '{print substr($0,length)}' \
| awk '{s+=$1} END {print s}'
Overall, this will print out a single number representing the total occurrences of a query from all text files in the directory. Let's dive into each section:
$ grep -c -i "e" *.txt
blah.txt:1
blah2.txt:0
find_results.txt:1
foo.txt:2
foo2.txt:2
foo3.txt:3
foo4.txt:2
grep outputs the count of string "e" in all text files in the directory, one line per file. But if I want just the numbers, the first awk command is introduced:
$ grep -c -i "e" *.txt | awk '{print substr($0,length)}'
1
0
1
2
2
3
2
substr takes the form of substr(string, start, end) so $0 is the input string (remember, $0 is a whole line). While we could have provided an integer (starting from 0) as start, we can also provide just length to tell the command to print the character at the end. Replacing length with length-1 results in the colon before each count to also be printed. We don't specify anything as the end since it is optional and not needed in this case.
Note that we could have also used cut here (introduced later in this article). The counts aren't really useful in this form, let's add them together, bringing us back to the original query:
$ grep -c -i "e" *.txt | awk '{print substr($0,length)}' \
| awk '{s+=$1} END {print s}'
11
The final command at the end of the piping will increment variable s by the value of $1, which represents the second field of the line. After the lines have been read, s is printed.
The command that is much more compact and simple that you could use for a use like the above is grep -i "e" *.txt | wc -l.
ln
ln makes links/references to a file or directories on your machine.
Hard link for files
When you don't specify the argument -s, ln will make a "hard" link. This means that your link reference points directly to a file itself in storage that contains the same contents as the selected file. Meaning, any action taken on either the link reference or selected file, the action is reflected on both. I'll demonstrate on a hard link for /Users/daniloradovic/Documents.
$ cat /Users/daniloradovic/Documents/test.txt
Hello there
$ ln /Users/daniloradovic/Documents/test.txt my-hard-link
$ cat my-hard-link
Hello there
$ echo "General Kenobi" >> my-hard-link
$ cat my-hard-link
Hello there
General Kenobi
$ cat /Users/daniloradovic/Documents/test.txt
Hello there
General Kenobi
my-hard-link, test.txt's contents also change. If you delete the link, the selected file is still intact. If you delete the selected file, the link will still exist.
$ rm /Users/daniloradovic/Documents/test.txt
$ cat /Users/daniloradovic/Documents/test.txt
cat: /Users/daniloradovic/Documents/test.txt: No such file or directory
$ cat my-hard-link
Hello there
General Kenobi
Symbolic link for files
When you use the argument -s, ln will make a "symbolic" link to the specified file. This is a reference to the location of the file. As with hard links, you can still take actions to edit the selected file through the symbolic link.
$ cat /Users/daniloradovic/Documents/test.txt
Hello there
$ ln -s /Users/daniloradovic/Documents/test.txt my-symbolic-link
$ cat my-hard-link
Hello there
$ echo "General Kenobi" >> my-symbolic-link
$ cat my-hard-link
Hello there
General Kenobi
$ cat /Users/daniloradovic/Documents/test.txt
Hello there
General Kenobi
my-symbolic-link, test.txt's contents also change. You can also run ls -la and see the link relationship defined
$ ls -la
lrwxr-xr-x 1 daniloradovic my-symbolic-link -> /Users/daniloradovic/Documents/test.txt
You can remove the link and the selected file is not deleted. However, if you remove the selected file, the symbolic link will point to nothing:
$ rm /Users/daniloradovic/Documents/test.txt
$ cat /Users/daniloradovic/Documents/test.txt
cat: /Users/daniloradovic/Documents/test.txt: No such file or directory
$ cat my-symbolic-link
cat: my-symbolic-link: No such file or directory
Symbolic link for directories
The command and behavior of symbolic links for directories is the exact same as the above for a file, but you provide the specified directory instead of a file
$ ln -s /Users/daniloradovic/Documents/testDir my-symbolic-directory-link
head
head -[num] [file] will return only the first [num] of your file.
$ head -3 bar.txt
test line 1
test line 2
test line 3
sed
sed is a stream editor, meaning it allows you to edit files inputted to it, straight from the command line. The catch is that the original file is not changed, but instead the new text is printed to stdout. sed can be used for finding, replacing, printing, and/or deleting text . The basic usage of sed for search and replace is sed 's/[pattern to replace]/[replacement pattern]/' [file name].replacement wil
$ cat foo.txt
Hello there
Who is there
Look over there
$ sed 's/there/here/' foo.txt
Hello here
Who is here
Look over here
$ cat foo.txt
Hello there
Who is there
Look over there
So we've replaced all instances of "there" with "here". And as mentioned, the original file foo.txt was not changed. Because of this, sed is super useful for copying files to new ones with small tweaks. It can also be used in a string of commands piped together (say, piping sed to sort to uniq).
Similarly, you can delete lines using sed with /d. Note that in the first example nothing is deleted because its not an exact match. In the second example the whole line "Hello there" is matched so it is deleted. In the third example we use -E for extended regex (regular expression) interpretations, which will delete "Who is there" because of the presence of "is".
$ cat foo.txt
Hello there
Who is there
Look over there
$ sed '/there/d' foo.txt
Hello there
Who is there
Look over there
$ sed '/Hello there/d' foo.txt
Who is there
Look over there
$ sed -E '/is/d' foo3.txt
Hello there
Look over there
If you want to edit or delete the actual contents of the file with /s or /d, you can use the argument -i.
Geeks For Geeks has a great article going more in depth with the usage of sed that is worth a read.
sort
sort sorts lines within text, or binary files. Lines can be delimited by newlines or NUL
'\0' characters. To set NUL as the separator, use the argument -z. To reverse in reverse order, use -r.
$ echo "zeppelin\nspark\natom\njava" | sort
atom
java
spark
zeppelin
uniq
uniq will read the input file (or stdin) and output only the unique lines. It is often used with grep and sort for better readability of logs.
$ echo "zeppelin\nzeppelin\nspark\natom\natom atom\njava" | sort | uniq
atom
atom atom
java
spark
zeppelin
curl
curl lets you transfer data to or from a server using a supported internet protocol. There are a ton listed out in man curl, but the most typical protocols are HTTP, HTTPS, FTP, and SCP.
One thing curl lets you do is identify which process, if any, is using a port on a host. In the example below I use localhost, which is for my local machine. Tip: the default IP address that localhost represents is 127.0.0.1
$ curl http://localhost:8000 -vscp
scp allows you to copy files/directories from one machine to another. The basic usage is
scp user@[host name]:[source path] [target path]
ps
ps prints out the process status for many processes. There are a ton of arguments you can checkout with man ps, but the most common usage is ps aux, which displays running process information across users, and processes with or without "controlling terminals". Basically, it displays an expanded and comprehensive list of processes compared to running just ps.
$ ps aux
USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND
root 29162 0.0 0.0 4286404 1060 s001 R+ 11:13PM 0:00.00 ps aux
cut
cut simply allows you to cut out specified characters from lines of a file. For basic usage, you can provide the delimiter -d, number of fields -f, and/or number of characters to print out -c.
To demonstrate the usage of -c let's print out the characters 4 to 6 of foo.txt (where 1 is the first character of a line):
$ cat foo.txt
hello : there : general : kenobi
A : surprise : to : be : sure : but : a : welcome : one
$ cut -c4-6 foo.txt
lo
su
cut -c-5-500 foo.txt (well outside the range of any line in the file), the command prints out the whole file.
Note that we put 4-6 immediately after -c; we could have also separate them with a whitespace, either works.
-d lets you specify the delimiter on which to cut the file lines. For example in foo.txt there's a ton of colons, so let's delimit on those
$cut -d: foo.txt
usage: cut -b list [-n] [file ...]
cut -c list [file ...]
cut -f list [-s] [-d delim] [file ...]
-d and the file name! As the output suggests, we need to provide some more arguments, mainly because even though now we know what we want to delimit on, cut doesn't know what part of the file to include or excluded based on the delimiter. So, we can provide -f to specify the fields to print. -f has multiple uses. The first is that you can provide just a single number to print out the n-th field between the delimiters:
$ cut -d: -f3 foo.txt
general
to
You could also use -f to specify ranges. For example 3-4 returns the 3rd and 4th instances of fields between the delimiters:
$ cut -d: -f3-4 foo.txt
general : kenobi
to : be
To cover all fields up to the n-th instance, use -n. To cover all fields starting from the n-th instance, use n-:
$ cut -d: -f3- foo.txt
general : kenobi
to : be : sure : but : a : welcome : one
$ cut -d: -f-3 foo.txt
hello : there : general
A : surprise : to
find
find will find specified files or directories in the path you specify.
The basic usage is
$ find [path to search in] [arguments] "[query string for files/directories]"* to match "any character(s)"
$find ~/Documents -name "blah*"
./blah.txt
./blah2.txt
$find ~/Documents -iname "*.txt"
./blah.txt
./foo.txt
./bar/test.txt
-iname is like name but case insensitive.
The above will return all results that match the criteria no matter how many levels deep in the directory from the starting path. To specify the depth, you can use -depth [number].
$ find ~/Documents -depth 4 -iname "*.txt"
This returns only the results at that depth, not everything from depth 1 to [number]. You can use -maxdepth [number] to return everything from depth 1 to [number].
$ find ~/Documents -maxdepth 4 -iname "*.txt"
You can also use -print0 to print the pathname of the selected files, followed by an ASCII NUL character (code 0):
$ find . -name "*.txt" -maxdepth 1 -print0
./foo.txt./blah2.txt./blah.txt./find_results.txt
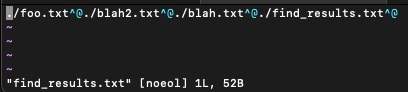
The above is just some simple examples; find is extremely powerful and has a ton of arguments that can make your searches very advanced. Go check them out with man find.
Recursive search in a directory
The easiest way of doing this is simply using grep and the -r flag to recursively search a directory at all levels.
$ grep -r "test" *
However, for the sake of making use of multiple commands, we can combine find and xargs to find usage of a query string in multiple files at all depths of a directory.
$ find . -name \*.txt -print0 | xargs -0 grep "test"
./level2folder/bar.txt:test line 1
./level2folder/bar2.txt:test line 2
./level2folder/bar3.txt:test line 3
.txt (note that we have to use the escape character version \*). The second half is passing that list of files to grep to search for "test". This is done with the help of xargs to provide grep the input, including the argument -0 for telling xargs to expect \0 as separators. The -0 argument is used in tandem with -print0 from find.
vim
vim is a program that allows you to view contents of a file and edit them; it is extremely powerful and has its own commands within the program itself. Besides the "need to knows" I cover in Part One, some more basic yet useful commands within vim are:
i |
enter insertion mode (you can modify the file as with a regular text editor) |
x |
delete the selected character |
u |
un-do the latest change |
control + r |
re-do an un-done change |
0 |
go to the beginning of the current line |
$ |
go to the end of the current line |
w |
go to start of the next word (word = alphanumeric string uninterrupted by whitespace, /, ;, etc) |
n |
go to end of the previous word (same word definition as above) |
W |
go to start of the next word (word = string uninterrupted by whitespace) |
B |
go to end of the previous word (same word definition as above) |
yy |
copy the line you're on (with the newline \n). See this article for a ton more useful options for copying and deleting |
y$ |
copy characters from the cursor to the end of the line you're on |
d + up arrow |
delete the line you're on and the line above |
d + down arrow |
delete the line you're on and the line below |
dd |
delete the line you're on |
d$ |
delete characters from the cursor to the end of the line you're on |
p |
paste any copied text |
v |
enter visual mode to select characters with arrows |
v"*y |
copy single character to clipboard |
v + [move cursor to select all wanted text] + "*y |
copy selected text to clipboard blah |
shift + g |
go to the end of the file |
gg |
go to the beginning of the file |
:q |
quit |
:q! |
forcefully quit |
:wq |
write and quit |
:wq! |
write and forcefully quit |
https://vim.rtorr.com/ contains a full guide, but the above is what I personally use.